

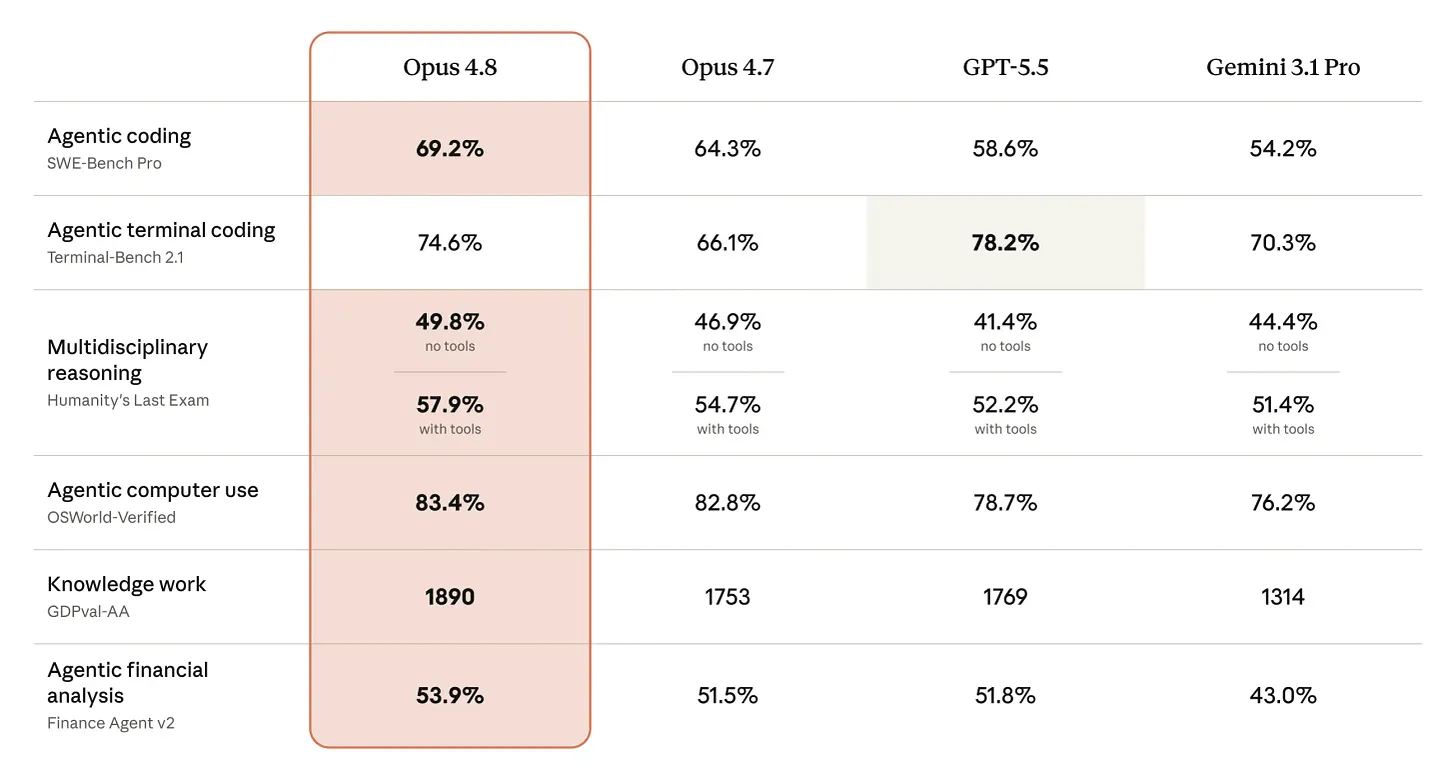
For agencies and operators building on AI, the model you prompt matters less than how you prompt it. Anthropic's Claude Opus 4.8 is the most capable model generally available — but most people leave the majority of that capability on the table because they never set the variables that actually control output quality.
Anthropic positions Opus 4.8 as an upgrade on Opus 4.7 with improvements across benchmarks and as a more effective collaborator, at the same price point. The framing is clear: 4.8 builds on 4.7's foundation rather than breaking from it. The prompting instincts you developed still apply — but there are meaningful new capabilities, and one genuinely new paradigm, that change what's achievable if you know how to use them.
The biggest addition is Dynamic Workflows in Claude Code: the ability for Claude to write its own orchestration scripts, spin up parallel subagents, and scale test-time compute trivially. We'll cover all of it below — the effort stack, XML structure, honesty directives, and the workflow paradigm.
This is the same framework we use at Fade Digital to run GEO research, build client deliverables, and pressure-test strategy. Below is everything you need to get the best output this model can produce, every single time.
Choose the right model
Before writing a single word of your prompt, choose the right model. Anthropic's current lineup includes Claude Opus 4.8, Claude Sonnet 4.6, and Claude Haiku 4.5 — each optimized for different workloads.
- Claude Opus 4.8 is the flagship. It excels at long-horizon autonomous tasks, complex reasoning, and knowledge work. It costs more and runs slower via the API, but when the task demands genuine thinking — strategic analysis, multi-step research, complex autonomous execution — nothing else in the generally available lineup comes close.
- Claude Sonnet 4.6 is the balanced workhorse: strong reasoning at faster speed and lower cost. For most everyday tasks, Sonnet covers roughly 80% of use cases well.
- Claude Haiku 4.5 is the speed specialist: fastest, cheapest, ideal for high-volume, straightforward tasks like classification, extraction, and summarization.
Start with Sonnet. Move to Opus when you need genuine cognitive depth, or when you're running a Dynamic Workflow that demands long-horizon coherence. Drop to Haiku when speed matters more than intelligence.
The framework
Anthropic's documentation describes a hierarchy of techniques ordered by impact. Most people jump straight to advanced techniques and skip the fundamentals. That's backwards. Here's the framework in the order that matters, updated for the specific behaviors of Opus 4.8.
Set the effort level (most important)
This is the single most important variable in your prompt, and most people never set it at all.
The effort parameter controls how much intelligence the model applies to a task. Like 4.7, Opus 4.8 respects effort levels strictly, especially at the low end. The system remains: low, medium, high (default), xhigh, and max.
One change from 4.7: Opus 4.8 defaults to high effort (4.7 defaulted to xhigh), which Anthropic says spends similar tokens on coding tasks while performing better. Adaptive thinking is off by default and must be explicitly enabled.

In the API:
client.messages.create(
model="claude-opus-4-8",
max_tokens=64000,
thinking={"type": "adaptive"},
output_config={"effort": "xhigh"},
messages=[{"role": "user", "content": "..."}],
)
When running at max or xhigh, set your max_tokens to at least 64k — the model needs room to think, reason, and execute across tool calls and subagents.
The floor has risen. At minimum effort, Opus 4.8 matches the peak performance of 4.7 at maximum effort on hard coding benchmarks. The ceiling expanded too — xhigh and max now unlock long-horizon agentic capabilities that 4.7 couldn't reach at any effort level.
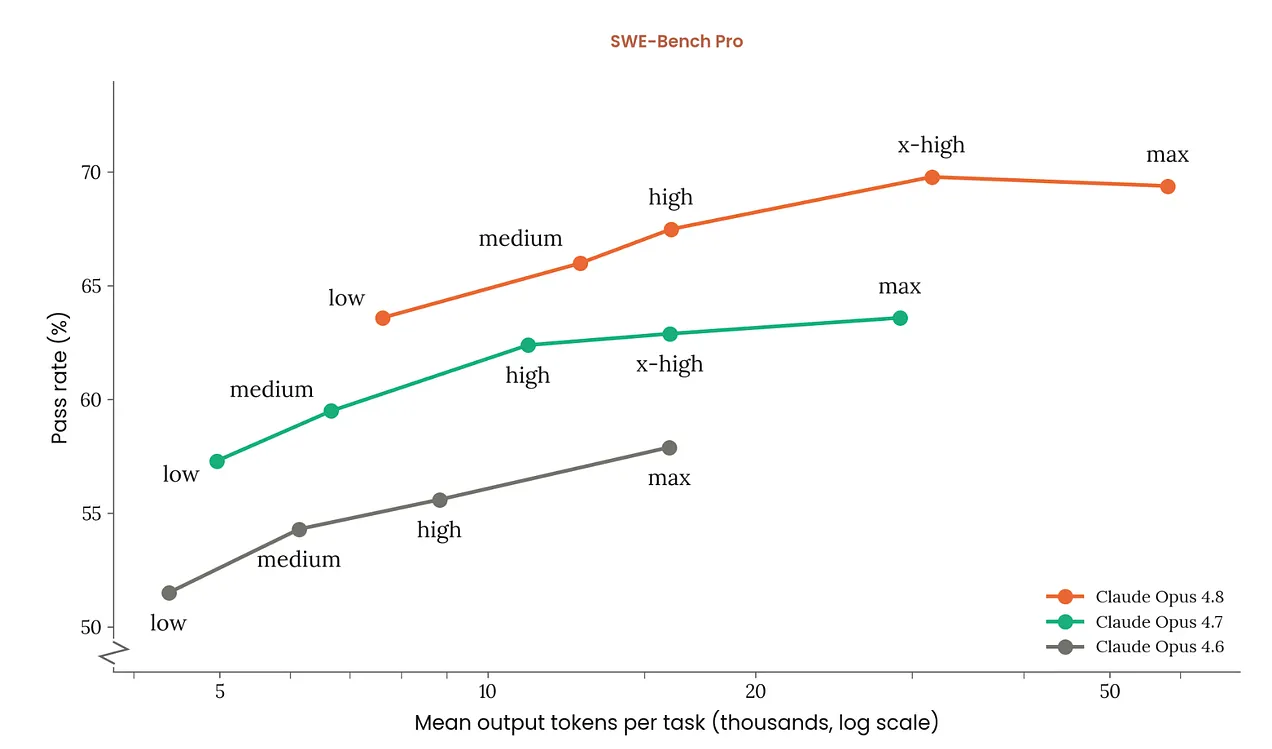
For Dynamic Workflows specifically, enable ultracode mode: this uses workflows aggressively without requiring you to ask for them every time.
If you see shallow reasoning on a complex task, raise the effort level before changing your prompt. That's almost always the correct fix.
Be specific — more than you think
The single highest-leverage prompting move is specificity. Opus 4.8, like 4.7, is extremely literal. Vague prompts get scoped, not generalized. If you want an instruction applied across all sections — not just the first — you have to say so. If you want exceptional output, you have to request it explicitly.
Think of your prompt as instructions to a brilliant but literal new hire on their first day. They'll do exactly what you say, so say exactly what you mean.
Weak prompt:
Write about market positioning.
Strong prompt:
Analyze the 3 most effective market positioning strategies for B2B
service businesses in a crowded category. For each strategy, explain
what's driving its effectiveness, provide one specific company example,
and assess whether it's likely to strengthen or weaken over the next
18 months. Apply this framework to all three strategies, not just
the first.
The difference isn't more words. It's more specificity, explicit scope, and a format directive at the end.
Use XML tags for structure
This is Claude's structural superpower, and still almost nobody uses it correctly. Claude was specifically trained to recognize XML tags as structural markers. When your prompt has multiple components — context, instructions, data, constraints, output format — XML tags prevent Claude from mixing them up.
<context>
You are helping me evaluate a new service line for a dental practice
currently doing $2.4M in annual revenue, growing 15% year over year.
</context>
<instructions>
Analyze the three key risks that most commonly derail practices
expanding into a new service line at this stage.
For each risk, explain the warning signs and what an owner should
be doing to mitigate them.
Apply this analysis to all three risks, not just the most obvious one.
</instructions>
<constraints>
- Be direct. Give me your honest assessment, not a balanced "it depends."
- Use specific examples from real businesses where possible.
- Flag any assumptions you're making.
- Maximum 600 words.
</constraints>
Claude sees the tags and immediately understands that <context> is background, <instructions> is the actual task, and <constraints> are the guardrails. Tag names are flexible — use whatever makes semantic sense: <background>, <rules>, <examples>, <output_format>. Consistency across your prompts matters more than the specific names.
Show Claude what good looks like
If one technique consistently separates good outputs from great ones, it's this: show Claude what good looks like. Instead of describing the tone, format, or style you want in abstract terms, provide two to three concrete examples. Claude pattern-matches against these far more reliably than it follows descriptive instructions alone.
<examples>
<example>
Input: "We need to cut 20% of the marketing budget"
Output: "Reducing marketing spend by 20% requires prioritization
across three areas: paid acquisition, agency retainers, and
tooling licenses. Here's a phased approach that preserves our two
highest-ROI channels..."
</example>
</examples>
Now analyze this situation using the same approach:
"We need to extend our runway by 6 months without cutting headcount"
Anthropic recommends 3–5 examples for best results. You can also ask Claude to evaluate your examples for relevance and diversity, or to generate additional ones based on your initial set.
Prompt for visible reasoning
For complex problems requiring analysis, multi-step reasoning, or strategic judgment, telling Claude to work through its reasoning before producing a final answer dramatically improves accuracy. The simplest version: add "Think through this step by step before giving your final answer" to your prompt.
The more structured version uses tags to separate reasoning from output:
<instructions>
Evaluate whether we should expand into a new metro market this year.
Before giving your recommendation, work through the analysis inside
<analysis> tags.
Consider: market size and growth, competitive landscape, our current
operational capacity, and capital required vs. expected payback period.
Then provide your final recommendation with a clear resource
allocation suggestion.
</instructions>
Forcing visible reasoning prevents Claude from pattern-matching to the most likely answer and back-filling justification after the fact.
Claude dynamically decides when and how to think based on the effort setting and task complexity. At high and xhigh effort, deep reasoning is largely automatic for demanding tasks. Extended thinking with a fixed budget_tokens is no longer supported — adaptive thinking is the only thinking-on mode, and it reliably outperforms the old fixed-budget approach.
Load rich context
Claude can only work with what you give it. The more relevant context you include, the more tailored and accurate the output becomes. Upload documents. Paste data. Provide company background. Share your goals. Explain your audience. Don't make Claude guess what you already know.
<background>
We're a home services company serving the Greater Toronto Area.
$4M annual revenue, ~30 staff, primarily HVAC and plumbing.
Our main competitors are large franchise operators and
independent contractors.
We differentiate on response time and transparent flat-rate pricing.
</background>
<data>
[Paste your quarterly metrics, customer feedback, or whatever's relevant]
</data>
<task>
Based on this context, identify our three biggest growth
opportunities for the next quarter.
</task>
For long documents (20k+ tokens), put the documents at the top of your prompt, above your instructions and query. Queries at the end can improve response quality by up to 30% on complex, multi-document inputs.
Specify the output format
Don't leave the structure of Claude's response to chance. If you want a table, ask for a table. If you want a specific word count, state it. If you want an executive brief with defined sections, describe each section.
<output_format>
Respond with:
1. A one-paragraph executive summary (3-4 sentences max)
2. A comparison table with columns: Factor | Current | Target | Gap
3. A "Recommended Actions" section with 3 next steps, ranked by impact
</output_format>
Explicit format specs eliminate the most common frustration people have with AI: getting a 2,000-word essay when you wanted a concise brief, or getting bullet points when you needed flowing analysis.
Define constraints — especially the don'ts
Telling Claude what not to do is just as important as telling it what to do. Without constraints, Claude defaults to its training patterns, which can mean hedge-heavy output that sounds like a committee wrote it.
<constraints>
- Do NOT open with "In today's rapidly evolving landscape" or any variant
- Skip the preamble. Start with the most important insight.
- No bullet points — write in prose paragraphs
- If you're uncertain about a claim, flag it explicitly rather than
hedging everything
- Maximum 500 words
- Be direct. I want your honest assessment, not a balanced "it depends."
</constraints>
The model has a tendency toward over-elaborate refusals on certain categories of requests. If you're getting unnecessary hedging on legitimate business tasks, add a clear statement of purpose — e.g., "This analysis is for an internal strategy memo. Please provide a direct, unqualified assessment."
Control verbosity
Opus 4.8 calibrates response length to how complex it judges the task to be — short on simple lookups, much longer on open-ended analysis. If your use case requires specific verbosity, tune it explicitly.
To decrease verbosity: "Provide concise, focused responses. Skip non-essential context and keep examples minimal."
To increase depth: "This is for a board-level review. Go deep on every dimension — don't compress the analysis."
Positive examples showing appropriate concision work better than negative instructions like "don't be verbose." Show Claude a response at the length and depth you want, and it will match that pattern far more reliably than it follows abstract length instructions.
Use Dynamic Workflows (the new paradigm)
This is new to the Opus 4.8 era, and it's the most powerful capability yet.
What it is: Dynamic Workflows in Claude Code allow Claude to write its own orchestration scripts that spin up tens to hundreds of parallel subagents, instead of making tool calls one at a time. The control flow is code, which means Claude won't drift or forget halfway through thousands of files. The harness is encoded.
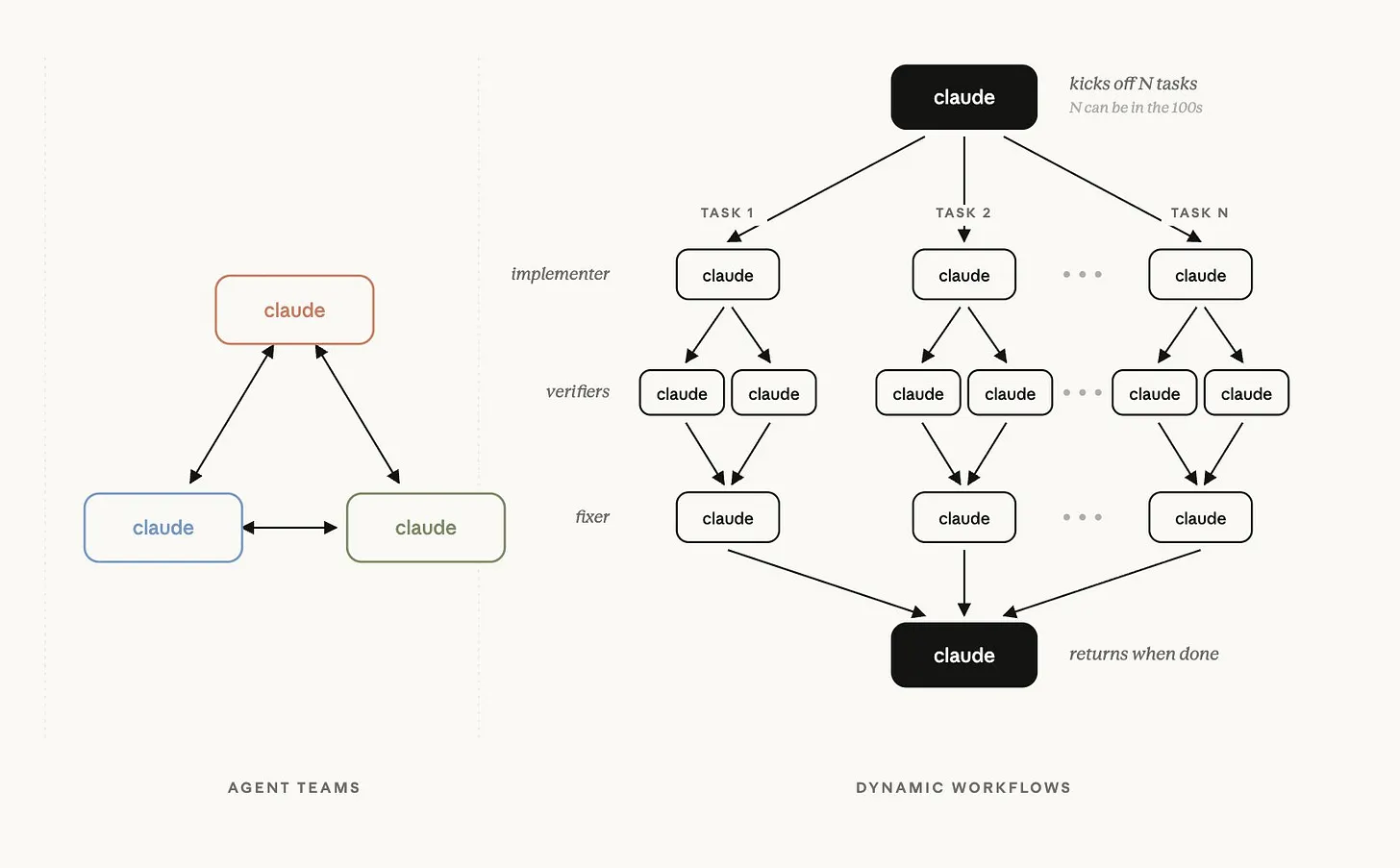
How it works: Mention the word "workflow" in any Claude Code prompt, and Claude will spin one up automatically. For aggressive workflow use without prompting, enable effort ultracode in your settings.
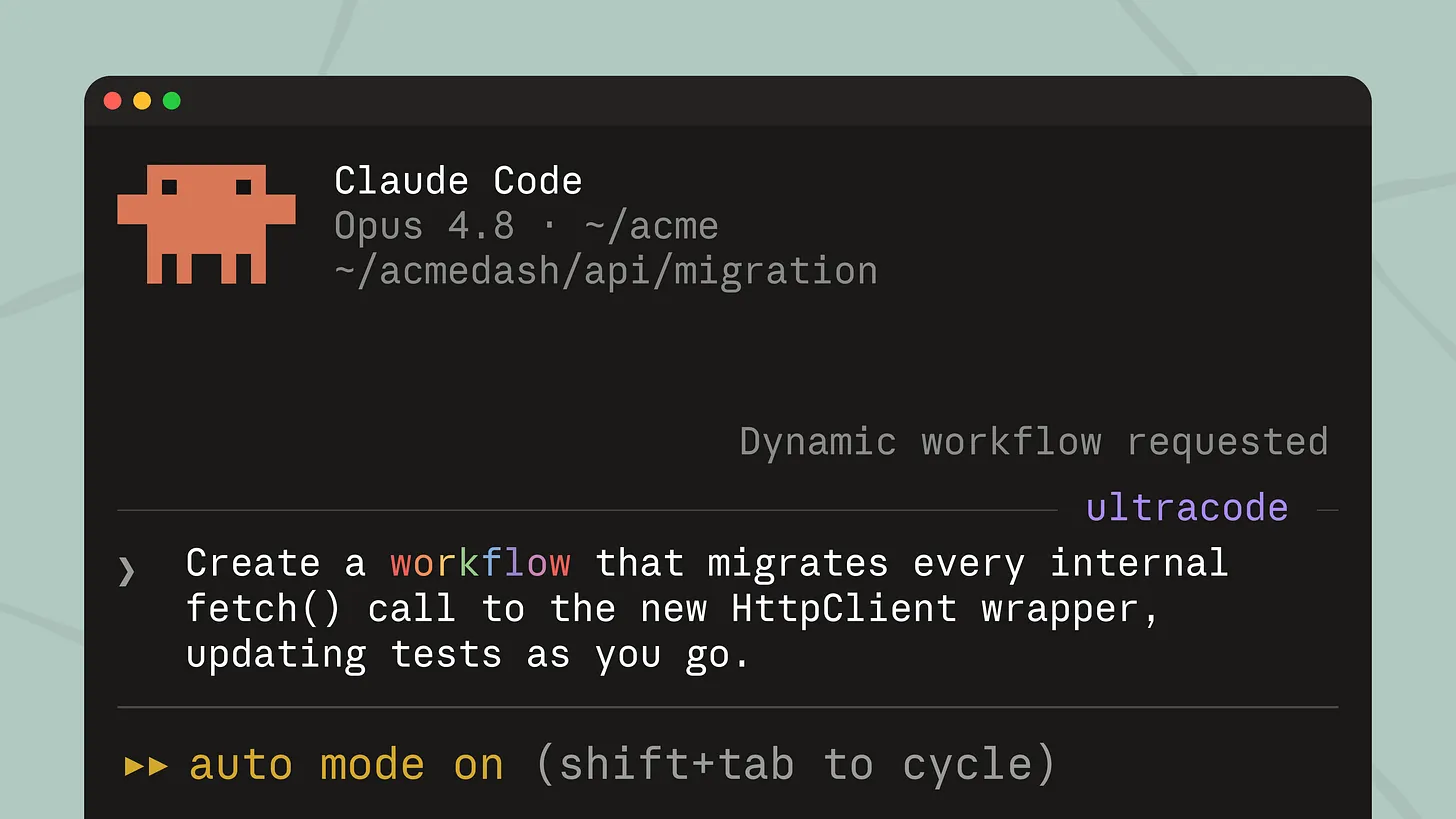
What it unlocks:
- Massively parallel execution: a small agent team can handle research-heavy tasks at a fraction of the latency of a single agent, while scoring higher. The orchestrator-with-blocking-subagents configuration reached the highest scores overall.
- Adversarial verification: route critical work through adversarial judges that each attack the output from a different lens. You can go as far as a tournament-style bracket, scoring competing plans against each other.
- Scalable test-time compute: workflows let you scale test-time compute trivially. There has never been an easier way to do this in Claude Code.
- Reusable automation: because workflows are scripts under the hood, you can save them, commit them to your repo, share them with your team, and turn them into skills.
Workflows can get expensive due to all the parallel agents. Get a feel for token usage on smaller tasks before unleashing them on larger ones. You can disable them with config or enterprise settings if needed.
Best practices for Dynamic Workflows:
- Trigger intentionally. Say "workflow" explicitly for important tasks. For routine work, keep workflows off to manage costs.
- Enable ultracode for coding sprints. In a focused engineering session,
effort ultracoderemoves the friction of triggering workflows manually. - Use adversarial judges for critical outputs. Don't just generate — verify. Route the output through a judge agent with explicit attack criteria.
- Save your best workflows as skills. If a workflow solves a recurring problem well, commit it. This is institutional knowledge that compounds.
- Set a token budget before large tasks. Ask Claude to estimate token usage before running a large workflow, then decide if the cost is justified.
- Use blocking subagents for accuracy-critical tasks. Async subagents reduce latency, but blocking subagents score highest when accuracy matters more than speed.
- Let Claude choose the architecture. Don't over-specify the workflow structure. Claude knows when to parallelize, when to serialize, and when to use a tournament bracket.
- Test on a sample first. On large codebases or research tasks, run the workflow on a representative 10% before committing to the full task.
Putting it all together
Here's what a properly structured Claude Opus 4.8 prompt looks like when you combine every technique above:
<context>
I run a multi-location service business ($8M revenue, 45 employees).
We're deciding whether to invest heavily in a new acquisition channel
now or optimize our existing channels for 18 months first.
Current cost per lead: trending up. Close rate: 22%. Payback: 8 months.
</context>
<instructions>
Analyze both options. Before giving your recommendation, work through
the trade-offs in <analysis> tags, considering:
- Current market conditions for our category
- Our metrics relative to typical benchmarks
- The risk/reward of investing now vs. optimizing first
- What we should use the 18 months to fix if we wait
Then provide a clear recommendation with a specific action plan.
Apply your analysis to both options equally — don't weight one by default.
</instructions>
<constraints>
- Be direct. Give me your honest read, not a balanced "it depends."
- Use specific benchmarks from comparable businesses where possible.
- Flag any assumptions you're making about market conditions.
- Keep the total response under 700 words.
</constraints>
<output_format>
1. Analysis (in <analysis> tags)
2. Recommendation (2-3 sentences, clear and direct)
3. 90-day action plan (5 specific actions, whichever path we choose)
</output_format>
This prompt is clear, structured, specific, and constrained. It tells Claude exactly what to do, how to think about it, what to avoid, and how to format the response. The output is categorically different from "Should I invest in a new channel now or wait?"