

Six months ago, the honest answer to "can AI just do my job?" was no — but it can do the annoying 20-minute parts of it. You'd ask a chatbot to draft an email, summarize a document, or write a snippet of code. It handled the task. You still owned the workflow — the stringing-together of fifty small tasks, the judgment calls, the knowing-what-to-do-next.
On June 9, 2026, that line moved. Anthropic released Claude Fable 5, and the thing people keep saying about it isn't "it writes better." It's "I handed it the whole project and walked away."
This is a guide for normal people — business owners, marketers, managers, curious humans — not AI researchers. We'll cover what Fable 5 is, what it's genuinely good at, what it costs in real dollars, the unusual safeguards Anthropic built into it, and exactly when it's worth reaching for. No hype, no jargon you'll have to Google.
What it is
Best at
Price
The catch
The 30-second version
If you only read this far: Claude Fable 5 is the strongest AI model Anthropic has ever released to the general public. It's especially good at long-running, complicated jobs — the kind that used to need a person babysitting the AI every few minutes. It costs $10 per million words-in and $50 per million words-out (roughly — we'll translate "tokens" below), which is less than half what its restricted sibling cost. And it ships with safety guardrails that, in rare cases, hand your request off to a slightly less powerful model. For more than 95% of what you'll ever ask it, you won't notice the guardrails at all.
Now the useful part — why "workflow, not a task" is the whole story.
What "replaces a workflow, not a task" actually means
Think about the difference between an intern and an employee.
You give an intern bite-sized, well-defined jobs: "format this spreadsheet," "draft a reply to this email." You check their work constantly. The moment a task has five steps and a fork in the road, you take over.
An employee, you hand the outcome. "Get our Q3 numbers into a board deck." They figure out the steps, hit a dead end, back up, try another way, and bring you something finished. You weren't in the room for the middle part.
Until now, AI was a very fast, occasionally brilliant intern. Fable 5 is the first one that behaves like the employee — it can stay on a single goal across hundreds of steps without losing the plot.
The old way: AI does a task
- You break the job into small pieces
- You prompt it one step at a time
- You catch its mistakes as you go
- You hold the plan in your head
- Great for: a draft, a summary, a snippet
Fable 5: AI runs the workflow
- You hand it the end goal
- It plans the steps itself
- It checks its own work and recovers from errors
- It keeps the plan in its memory across hours
- Great for: a migration, an analysis, a whole app
Anthropic's own framing backs this up: "The longer and more complex the task, the larger Fable 5's lead over our other models." In plain terms — on a quick question, Fable 5 is only a little better than what you already had. On a sprawling, day-long project, it's in a different league.
The clearest real example came from the payments company Stripe, which tested Fable 5 before launch. They pointed it at a 50-million-line codebase — a genuinely enormous software project — and asked it to perform a site-wide upgrade. It finished in a single day a job their engineers estimated would have taken a full team more than two months by hand. That's not "AI helped write some code." That's an entire multi-week workflow, compressed.
What Claude Fable 5 actually is (in plain English)
Anthropic builds Claude models in tiers. You may know Haiku (small and fast), Sonnet (the everyday workhorse), and Opus (the heavyweight). Above all of those sits a new tier they call Mythos-class — models powerful enough that Anthropic was initially cautious about who could use them.
The first Mythos-class model, Claude Mythos Preview, was released back in April only to a small circle of cybersecurity defenders and government partners. It was considered too capable to hand to the public without stronger safety work.
Claude Fable 5 is that same league of capability, finally made safe enough for everyone. Anthropic describes it as "a Mythos-class model that we've made safe for general use." The name is a nice touch: Fable comes from the Latin for "that which is told," a cousin of the Greek mythos — same family, different temperament. Fable is the version with guardrails on; its restricted twin, Mythos 5, is the same brain with some guardrails removed, available only to vetted cyber and biology researchers.

For you, the headline is simple: this is the most capable AI Anthropic has ever put in front of the general public, and you can use it today through Claude, the Claude app, and the major cloud platforms.
What it's genuinely great at
Anthropic and its early-access customers tested Fable 5 hard. Here's what it's best at — translated out of benchmark-speak into what it means for a real person.
Software engineering — building and fixing software. This is Fable 5's standout strength. Beyond the Stripe migration, the model can work on a coding problem for hours, test its own work, hit errors, and fix them without a human nudging it. If you run a business with any custom software, this is the difference between "the AI suggests code our developers paste in" and "the AI ships the feature."
Knowledge work — analysis, research, documents. On a senior-level finance benchmark built by the firm Hebbia, Fable 5 scored highest of any model, with big gains in reading charts and tables, reasoning across long documents, and actual problem-solving. The trading firm IMC said it "aced their trading-analysis evaluations nearly across the board." Translation: it's not just summarizing your reports, it's reasoning about them the way a sharp analyst would.
Vision — understanding images and screenshots. Fable 5 is the new best-in-class at "seeing." It can pull exact numbers out of a dense scientific chart, and — memorably — rebuild a working app's source code from screenshots alone. Anthropic's fun proof point: earlier Claude models needed elaborate helper tools to play the video game Pokémon FireRed; Fable 5 beat the whole game using nothing but raw screenshots of the screen.
Memory — staying on track for hours. Most AI loses the thread on long jobs. Fable 5 keeps focus across millions of words of context and gets better by taking its own notes as it works. When Anthropic let it play the strategy game Slay the Spire with a notebook to remember past moves, its performance improved three times more than the previous top model's.
Science — and this is the genuinely staggering part. Using the unrestricted Mythos 5 twin, Anthropic's scientists sped up parts of drug design roughly tenfold, with the model independently choosing experiments and recovering from failures the way a trained scientist does. It also produced original molecular-biology hypotheses that experts preferred about 80% of the time over a previous model's — and at least one was later confirmed by a separate lab. You won't be designing proteins on a Tuesday afternoon, but it tells you how much real reasoning is under the hood.
The throughline
Every one of these strengths is about endurance and judgment, not just raw smarts. Fable 5 doesn't just answer faster — it stays on a hard problem longer, corrects itself, and finishes. That's the workflow-replacing behavior in a sentence.The benchmarks, decoded
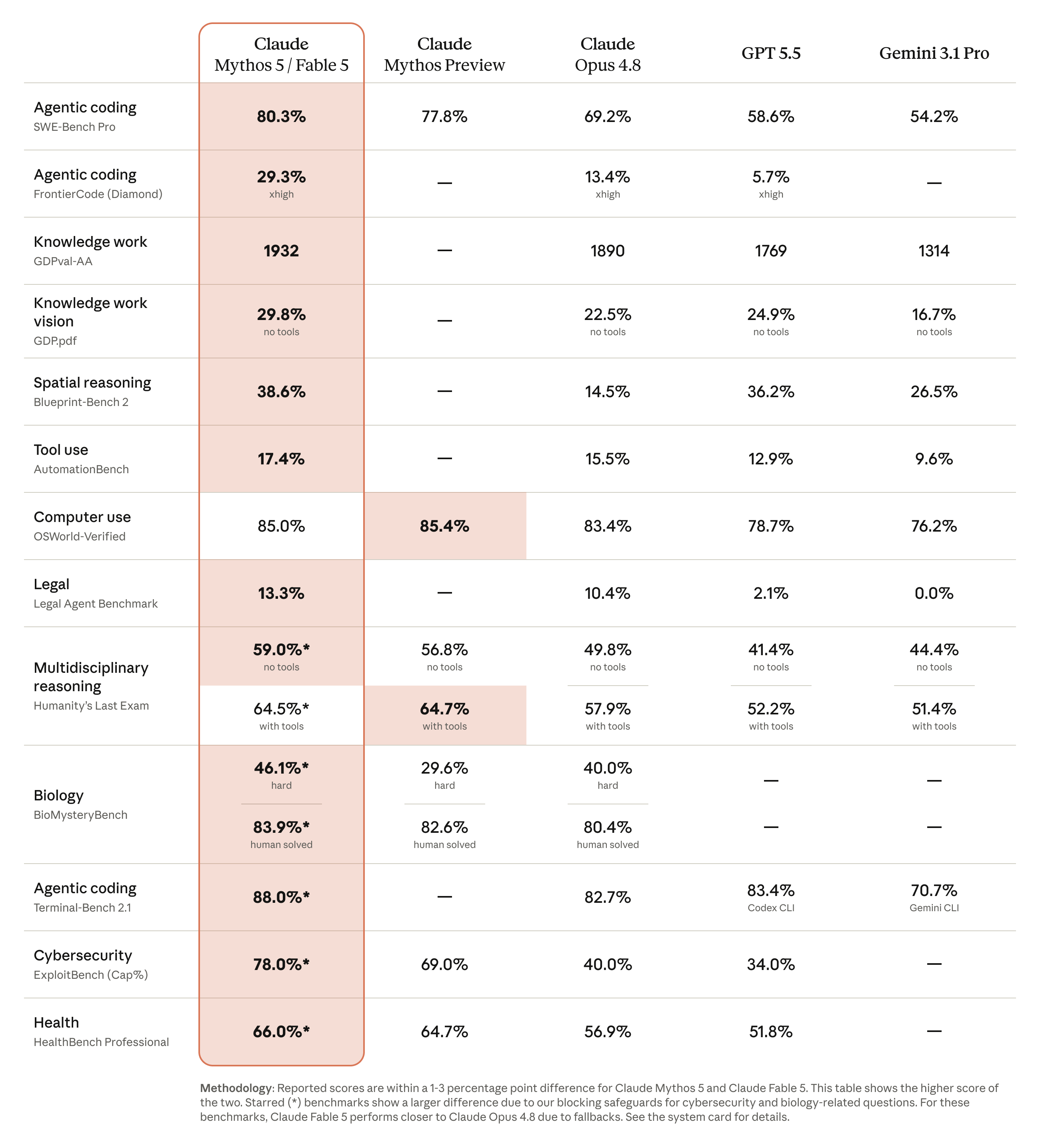
"Benchmarks" are just standardized tests for AI — the SATs of the model world. They're imperfect, but they let you compare models on the same yardstick. Below is an interactive look at how Fable 5 stacks up against the other leading models of mid-2026. Tap a category to switch.
A few of those deserve a plain-English caption:
- SWE-Bench Pro measures whether an AI can fix real, messy software problems from start to finish. Fable 5's 80% means it solved four out of five — a level that genuinely changes what a small dev team can ship.
- FrontierCode (Diamond) is the hardest coding test here, on purpose. Notice the numbers are low for everyone — that's the point. Fable 5's 29% is more than double the next model. The frontier is still hard; Fable 5 is just further up it.
- Humanity's Last Exam is a brutal, broad reasoning test. Fable 5 leads, but no model is "acing" it — a healthy reminder that these tools are powerful, not omniscient.
- Cybersecurity (ExploitBench) is where Fable 5's lead is widest and most carefully guarded — more on that in the safeguards section. (This score reflects the model's raw skill; as you'll see, the safeguards stop everyday users from actually wielding it.)
What does it actually cost?
AI is priced per token. A token is a chunk of text — about ¾ of a word. So one million tokens is roughly 750,000 words, or about five full-length novels of text going in or out.
Fable 5 costs $10 per million tokens of input (what you send it) and $50 per million tokens of output (what it writes back). For comparison, that's less than half the price of the restricted Mythos Preview model. There's also a 90% discount on repeated input when you reuse the same context (called prompt caching), and a slightly higher rate (1.1×) if you need the work to run on US-only servers.
Numbers in the abstract are meaningless, so here's a calculator. Pick a realistic job and see what it'd actually cost in dollars:
Rough estimate at $10 / $50 per million tokens. Real usage varies; prompt caching can cut input cost up to 90%.
The pattern to notice: simple jobs are pennies. Even a heavy, all-day coding workflow lands in single-digit-to-low-tens of dollars — next to a developer's hourly rate, that's a rounding error. The cost only becomes real at sustained team-scale volume, which is exactly where you'd be measuring it against salaries anyway.
One more cost wrinkle worth knowing if you pay for Claude personally: at launch, Fable 5 is included free on Pro, Max, Team, and Enterprise plans through June 22, 2026. After June 23 it shifts to usage-credit billing while Anthropic manages demand, with the stated intention of folding it back into standard plans once capacity allows. So if you want to kick the tires at no extra cost, the first couple of weeks are the window.
Real-world use cases for everyday people
Forget protein design. Here's what Fable 5's "run the whole workflow" ability looks like for ordinary work.
First, see it in motion — Anthropic's launch walkthrough shows the model planning and executing whole projects on its own:
"Introducing Claude Fable 5." Source: Anthropic on YouTube.
Now pick a role below to see exactly which workflow it takes off your plate — the goal you hand it, the steps it runs on its own, and what comes back:
Here are those same five, in detail:
1. The small-business owner who hates bookkeeping. You drop in a year of bank statements and receipts and say: "Build me a clean profit-and-loss statement, flag anything that looks like a duplicate charge or a subscription I forgot about, and write me two paragraphs on where my money actually went." The old AI could summarize one statement. Fable 5 works through all twelve months, reconciles them, catches the $40/month tool you stopped using in March, and hands you the finished P&L plus the plain-English story. That's an afternoon with your accountant, done before your coffee's cold.
2. The non-technical founder who wants to build an app. You describe the simple tool you wish existed — "a booking page where clients pick a time and it texts me." One of Anthropic's launch partners — an app-building platform — put it bluntly: "Apps that took a hundred prompts a year ago, it now one-shots." You're not learning to code. You're describing the outcome and getting a working thing back, then refining it in conversation.
3. The lawyer or contracts manager. Hand Fable 5 a stack of vendor agreements and your company's standard positions, and ask it to redline them. A legal-tech partner reported that in blind review, "its redlines matched or beat our current model every time." For a small firm without a junior associate to do first-pass markup, that's a genuine capability unlock — with the obvious caveat that a human still signs off.
4. The analyst buried in spreadsheets. Anthropic's testing partner for everyday spreadsheet work found Fable 5 beat the previous top model "at every effort level… finishing runs 25–30% faster." The real-world version: "Take these three messy exports, clean them, join them, and build me the five charts I show the leadership team every month." It does the whole chain, not just one cleanup step.
5. The marketer or content lead. Point it at your product, three competitor pages, and your last quarter's performance, and ask for a content plan and the first drafts and the meta descriptions — as one job. Because it can hold the whole picture in memory, the drafts actually reflect the strategy it just built, instead of you copy-pasting context between ten separate chats.
The common thread: in every case, you're delegating a process, not requesting a paragraph. That's the shift.
The safeguards — and what they mean for ordinary Joes
Here's the part that makes Fable 5 unusual, and it's worth understanding rather than fearing.
A model this capable is genuinely dual-use. The same skill that lets it find and fix a security hole in your software could, in the wrong hands, help someone attack software. The same biology reasoning that speeds up drug discovery could, in the wrong hands, help design something dangerous. Anthropic's solution isn't to make the model dumber — it's to put a bouncer at the door for a narrow set of high-risk topics.
Technically, Fable 5 ships with separate AI "classifiers" — small watchdog systems that scan requests touching cybersecurity, biology/chemistry, or attempts to copy the model itself ("distillation"). If a request trips one of these wires, your answer is quietly handled by Anthropic's next-best model, Claude Opus 4.8, instead of Fable 5 — and you're told when it happens.
Why this is smart, not annoying, for normal users:
- You almost never hit it. Anthropic says more than 95% of all Fable 5 sessions involve no fallback whatsoever. For those sessions, you're getting the full Mythos-class brain.
- A fallback isn't a refusal. Older safety systems just said "I can't help with that." Here, you still get a real, capable answer from Opus 4.8 — itself one of the best models on earth. Most people wouldn't notice the handoff if they weren't told.
- It's deliberately over-cautious right now. Anthropic admits the guardrails are tuned conservatively and will occasionally flag harmless questions (a security professional or a biology teacher might get bounced to Opus). They've said reducing these false alarms is a priority in the weeks after launch.
In a typical 100 sessions, the safeguards change the response in roughly this many:
~95+ of every 100 sessions run on full Fable 5. The highlighted few fall back to Claude Opus 4.8 — still a top-tier answer, just from the safer model.
One more thing that affects you indirectly: for these Mythos-class models, Anthropic now keeps business traffic for 30 days to help catch novel attacks and reduce those false alarms. Importantly, they've stated this data won't be used to train future models and is deleted after 30 days. If you're handling sensitive material, that's a policy worth reading in full — but the short version is it's a security measure, not a data-harvesting one.
So for an ordinary Joe: use it normally, and you'll likely never see a guardrail. If you ever get a note saying your answer came from Opus 4.8, that's the system working as designed — you got a great answer, and a genuinely dangerous version of that same question got the same treatment.
When you should not reach for Fable 5
Being honest is part of being useful, so: Fable 5 is not the right tool for everything.
If your job is quick and well-defined — a short email, a quick rewrite, a simple question — you're overpaying in both money and time. Anthropic's smaller models (Haiku and Sonnet) are faster and far cheaper, and you genuinely won't notice a quality difference on easy work. Reaching for Fable 5 to write a tweet is like renting a forklift to carry a grocery bag.
The rule of thumb:
- Short, simple, high-volume → Haiku or Sonnet.
- Important but bounded (a solid analysis, a real draft) → Opus 4.8 is plenty.
- Long, complex, multi-step, high-value — the kind of job that used to need a person all day → this is where Fable 5 earns its price many times over.
And a practical note: Anthropic expects demand to be very high, so subscription access is rolling out in stages. If you hit a capacity message, that's why — not a problem on your end.
The bottom line
For two years, the honest pitch for AI was "a brilliant assistant that needs supervision." Claude Fable 5 is the first model that credibly moves from assistant to operator — something you can hand an outcome to and trust to run the messy middle.
It won't replace your judgment, your relationships, or your accountability. What it replaces is the workflow — the dozens of small steps between deciding what you want and having it done. For the long, tedious, multi-step projects that eat your week, that's not a small upgrade. It's a different category of tool.
If you want to feel the difference yourself, the smartest move is to try it during the free-access window on a paid Claude plan before June 23, 2026 — and don't test it on something easy. Hand it a whole project, the kind you'd normally block out a day for, and watch how far it gets on its own. That's where the "workflow, not a task" claim stops being marketing and starts being obvious.